重み付きGauss-Newton
Gauss-Newton法はその収束の速さからさまざまな場面で扱われる数理最適化手法であるが、一般的に誤差関数として二乗誤差を用いるため、外れ値に弱いという問題がある。
ここでは外れ値に対して頑強な誤差関数とその最適化手法について解説する。例として point-set registration を取り扱うが、ここで解説する手法は他のさまざまな最適化問題にも適用することができる。
問題設定
最適化問題のパラメータを \(\mathbf{\beta} = \{\mathbf{q}, \mathbf{t}\}\) で表現する。ここで \(\mathbf{q} \in \mathbb{H}\) は回転を表す四元数、 \(\mathbf{t} \in \mathbb{R}^{3}\) は並進を表す3次元ベクトルである。
2つの3次元点群の集合をそれぞれ \(P\) と \(U\) とする。
\[\begin{split}\begin{align}
P &= \{\mathbf{p}_{i}\},\,\mathbf{p}_{i} \in \mathrm{R}^{3},\,i=1,...,n \\
U &= \{\mathbf{u}_{j}\},\,\mathbf{u}_{j} \in \mathrm{R}^{3},\,j=1,...,n
\end{align}\end{split}\]
Point-set registration とは、これら点群を用いてなんらかの誤差関数 \(E\) を設定し、それを最小化することで、これら点群の間の尤もらしい変換 \(\mathbf{\beta} = \{\mathbf{q}, \mathbf{t}\}\) を求める問題である。
\[\underset{\mathbf{\beta}}{\arg\min}\, E(P, U;\, \mathbf{\beta}),\]
誤差関数には一般的に平均二乗誤差がよく用いられる。
\[\begin{split}\begin{align}
\mathrm{MSE}(P, U; \mathbf{\beta}) &= \frac{1}{n} \sum_{i=1}^{n} || \mathbf{r}(\mathbf{p}_{i}, \mathbf{u}_{i};\, \mathbf{\beta}) ||^{2} \\[10pt]
&\text{where}\quad\mathbf{r}(\mathbf{p}_{i}, \mathbf{u}_{i};\, \mathbf{\beta}) = R(\mathbf{q}) \cdot \mathbf{p}_{i} + \mathbf{t} - \mathbf{u}_{i}
\end{align}\end{split}\]
\(\mathbf{p}_{i}\) と \(\mathbf{u}_{i}\) はパラメータ \(\mathbf{\beta}\) の変化の影響を受けない値であり、 \(n\) も最適化のプロセス内では固定値として扱えるので、簡単のために誤差関数を \(E_{s}\) としてこう表記しておこう。
\[\begin{split}\begin{align}
E_{s}(\mathbf{\beta}) &= \sum_{i=1}^{n} e_{i}(\mathbf{\beta}) \\[10pt]
e_{i}(\mathbf{\beta}) &= || \mathbf{r}_{i}(\mathbf{\beta}) ||^{2} = \mathbf{r}_{i}(\mathbf{\beta})^{\top}\mathbf{r}_{i}(\mathbf{\beta}) \\[10pt]
\mathbf{r}_{i}(\mathbf{\beta}) &= R(\mathbf{q}) \cdot \mathbf{p}_{i} + \mathbf{t} - \mathbf{u}_{i}
\end{align}\end{split}\]
外れ値に対する脆弱性
さて、ここで問題がある。平均二乗誤差は外れ値に弱いため、入力データ \(P,\, U\) に少しでも外れ値が含まれていると、パラメータの推定結果 \(\hat{\mathbf{\beta}}\) は真の値 \(\mathbf{\beta}^{*}\) から大きく外れてしまう。
外れ値に対する頑強性の確保
この問題に対処するための方法は数多く提案されており、ここではGauss-Newtonの最適化プロセスとともによく用いられる重み付けGauss-Newton法を紹介する。
これはある関数 \(\rho\) を導入することで、平均二乗誤差よりも外れ値の影響を受けにくくする手法である。
\[E_{\rho}(\mathbf{\beta}) = \sum_{i=1}^{n} \rho(\tilde{e}_{i}(\mathbf{\beta})),\,\quad\tilde{e}_{i}(\mathbf{\beta}) = \frac{e_{i}(\mathbf{\beta})}{\sigma_{MAD}}\]
関数 \(\rho\) はしばしば入力値の標準偏差が1に正規化されていることを仮定する。 \(\sigma_{MAD}\) は \(e_{i}\) の標準偏差の推定値であり、これで正規化を行っている。
また、データに外れ値が含まれていることを仮定するため、標準偏差の計算には外れ値に対して頑強な計算手法が用いられる。詳しくは別項で解説する。
\[\sigma_{MAD}=\frac{\operatorname{MAD}}{\Phi^{-1}(\frac{3}{4})},\quad\operatorname{MAD}=\operatorname{median}_{i}(\left|e_{i}−\operatorname{median}_{j}(e_{j})\right|)\]
\(\rho\) にはさまざまなものが提案されており、たとえば huber loss
\[\begin{split}\rho(e) = \begin{cases}
e, & \text{if } e\lt k^2\\
2k\sqrt{e} - k^2, & \text{if } e\geq k^2\\
\end{cases}\end{split}\]
などがよく用いられる。
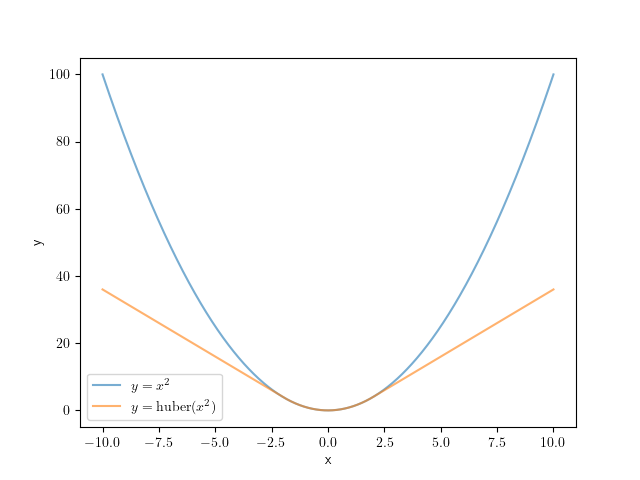
通常の二乗誤差とHuber関数の比較(k=2.0)。二乗誤差と比較すると、Huber関数は大きな残差を持つサンプルに対して小さな誤差を割り当てるため、外れ値の影響が小さくなる。
通常の二乗誤差は大きな残差 \(\mathbf{r}_{i}\) を持つサンプル(外れ値)に対して大きな誤差 \(e_{i}\) を割り当てる。最適なパラメータ \({\arg\min}_{\mathbf{\beta}} E_{s}\) を求める際には、外れ値に対応する誤差を重点的に減少させようとしてしまい、結果として推定値 \(\hat{\mathbf{\beta}}\) が外れ値に引っ張られてしまう。一方でHuber関数などは外れ値が生み出す誤差を \(\rho(e_{i})\) として抑制するため、外れ値を重点的に扱うことはせず、結果としてロバストな推定ができるようになる。
Gauss-Newton法による誤差最小化
さて、外れ値に対する頑強性を確保する関数 \(\rho\) を導入したので、これ考慮しつつ誤差 \(E_{\rho}(\mathbf{\beta})\) を最小化する方法を導出しよう。
通常のGauss-Newton法と同じ枠組みで誤差最小化を行う。\(\mathbf{\beta}_{0}\) は初期値として固定されているため、 \(\mathbf{\delta}\) のみを変動させ、誤差の値の変化を観察すればよい。
ある値 \(\mathbf{\beta}_0\) の周辺で関数 \(E_{\rho}\) を近似し、これを最小化するパラメータ \(\mathbf{\beta}_0 + \mathbf{\delta}^{*},\,\mathbf{\delta}^{*} = {\arg\min}_{\mathbf{\delta}}\, E_{\rho}(\mathbf{\beta}_0 + \mathbf{\delta})\) を求めよう。
微小な変数 \(\Delta \mathbf{\delta}\) を導入し、 \(E_{\rho}\) を微分してその変化を観察することで、\(E_{\rho}\) を \(\mathbf{\beta}_{0}\) の周辺で局所的に最小化するパラメータ \(\mathbf{\beta}_{0} + \mathbf{\delta}\) を見つけることができる。
\[\begin{split}\begin{align}
\frac{\partial E_{\rho}(\mathbf{\beta})}{\partial \mathbf{\beta}}\Big|_{\mathbf{\beta}_{0} + \mathbf{\delta}}
&=
\lim_{\Delta\mathbf{\delta} \to \mathbf{0}}
\frac{E_{\rho}(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta}) - E_{\rho}(\mathbf{\beta}_{0} + \mathbf{\delta})}
{(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta}) - (\mathbf{\beta}_{0} + \mathbf{\delta})} \\
&=
\lim_{\Delta\mathbf{\delta} \to \mathbf{0}}
\sum_{i=1}^{n}
\left[
\frac
{\rho(\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta})) - \rho(\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta}))}
{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta}) - \tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}
\cdot
\frac
{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta}) - \tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}
{(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta}) - (\mathbf{\beta}_{0} + \mathbf{\delta})}
\right] \\
&=
\lim_{\Delta\mathbf{\delta} \to \mathbf{0}}
\sum_{i=1}^{n}
\left[
\frac
{\partial \rho}{\partial \tilde{e}_{i}}\Big|_{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}
\cdot
\frac
{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta}) - \tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}
{\Delta\mathbf{\delta}}
\right]
\end{align}\end{split}\]
\(\frac{\partial E_{\rho}(\mathbf{\beta})}{\partial \mathbf{\beta}}\Big|_{\mathbf{\beta}_{0} + \mathbf{\delta}} = \mathbf{0}\) とおけば最適なパラメータ \(\mathbf{\beta}_{0} + \mathbf{\delta}^{*}\) を導出することができるだろう。
\(\mathbf{r}_{i}\) の微分を \(J_{i}\) とおいて、関数 \(\tilde{e}_{i}\) を近似する。
\[J_{i}(\mathbf{\beta}_{0})
=
\frac{\partial \mathbf{r}_{i}}{\partial \mathbf{\beta}}\Big|_{\mathbf{\beta}_{0}}
=
\lim_{\Delta\mathbf{\beta} \to \mathbf{0}} \frac{\mathbf{r}_{i}(\mathbf{\beta}_{0} + \Delta\mathbf{\beta}) - \mathbf{r}_{i}(\mathbf{\beta}_{0})}{\Delta\mathbf{\beta}}\]
\[\begin{split}\begin{align}
\tilde{e}_{i}(\mathbf{\beta}_{0} + \Delta\mathbf{\beta})
&=
\frac{1}{\sigma_{MAD}} \cdot e_{i}(\mathbf{\beta}_{0} + \Delta\mathbf{\beta}) \\
&=
\frac{1}{\sigma_{MAD}} \cdot \mathbf{r}_{i}(\mathbf{\beta}_{0} + \Delta\mathbf{\beta})^{\top} \mathbf{r}_{i}(\mathbf{\beta}_{0} + \Delta\mathbf{\beta}) \\
&\approx
\frac{1}{\sigma_{MAD}} \cdot \left[
\mathbf{r}_{i}(\mathbf{\beta}_{0}) + J_{i}\Delta\mathbf{\beta}]^{\top} [\mathbf{r}_{i}(\mathbf{\beta}_{0}) + J_{i}\Delta\mathbf{\beta}
\right] \\
&=
\frac{1}{\sigma_{MAD}} \cdot \left[\mathbf{r}_{i}(\mathbf{\beta}_{0})^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0}) +
2\Delta\mathbf{\beta}^{\top}J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0}) +
\Delta\mathbf{\beta}^{\top}J_{i}^{\top}J_{i}\Delta\mathbf{\beta} \right]
\end{align}\end{split}\]
この結果を利用すると、 \(\tilde{e}_{i}\) の微分を簡易な式で近似することができる。
\[\begin{split}\begin{align}
&\tilde{e}_{i}(\mathbf{\beta}_{0} + (\mathbf{\delta} + \Delta\mathbf{\delta})) - \tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta}) \\
&\approx
\frac{1}{\sigma_{MAD}} \cdot
\left\{
[\mathbf{r}_{i}(\mathbf{\beta}_{0})^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
+ 2(\mathbf{\delta} + \Delta \mathbf{\delta})^{\top}J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
+ (\mathbf{\delta} + \Delta \mathbf{\delta})^{\top}J_{i}^{\top}J_{i}(\mathbf{\delta} + \Delta \mathbf{\delta})]
- [\mathbf{r}_{i}(\mathbf{\beta}_{0})^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
+ 2\mathbf{\delta}^{\top}J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
+ \mathbf{\delta}^{\top}J_{i}^{\top}J_{i}\mathbf{\delta}]
\right\} \\
&= \frac{1}{\sigma_{MAD}} \cdot \left[ 2\Delta \mathbf{\delta}^{\top}J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
+ 2\Delta \mathbf{\delta}^{\top}J_{i}^{\top}J_{i}\mathbf{\delta}
+ \Delta \mathbf{\delta}^{\top}J_{i}^{\top}J_{i}\Delta \mathbf{\delta} \right]
\end{align}\end{split}\]
\[\begin{split}\begin{align}
\lim_{\Delta\mathbf{\delta} \to \mathbf{0}}
\frac{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta} + \Delta\mathbf{\delta}) - \tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}{\Delta\mathbf{\delta}}
&\approx
\frac{1}{\sigma_{MAD}} \cdot
\lim_{\Delta\mathbf{\delta} \to \mathbf{0}}
\frac{
2\Delta \mathbf{\delta}^{\top}J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
+ 2\Delta \mathbf{\delta}^{\top}J_{i}^{\top}J_{i}\mathbf{\delta}
+ \Delta \mathbf{\delta}^{\top}J_{i}^{\top}J_{i}\Delta \mathbf{\delta}}{\Delta\mathbf{\delta}} \\
&=
\frac{1}{\sigma_{MAD}} \cdot
\lim_{\Delta\mathbf{\delta} \to \mathbf{0}}
\left[
2J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
+ 2J_{i}^{\top}J_{i}\mathbf{\delta}
+ J_{i}^{\top}J_{i}\Delta \mathbf{\delta}
\right] \\
&=
\frac{2}{\sigma_{MAD}} \cdot (J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0}) + J_{i}^{\top}J_{i}\mathbf{\delta})
\end{align}\end{split}\]
結果として、誤差関数の微分は
\[\begin{align}
\frac{\partial E_{\rho}(\mathbf{\beta})}{\partial \mathbf{\beta}}\Big|_{\mathbf{\beta}_{0} + \mathbf{\delta}}
&\approx
\frac{2}{\sigma_{MAD}} \cdot
\sum_{i=1}^{n}
\left[
\frac
{\partial \rho}{\partial \tilde{e}_{i}}\Big|_{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}
\cdot
(J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0}) + J_{i}^{\top}J_{i}\mathbf{\delta})
\right]
\end{align}\]
となり、これを \(\mathbf{0}\) とおけば線型方程式が得られる。
\[\begin{align}
\sum_{i=1}^{n}
\frac{\partial \rho}{\partial \tilde{e}_{i}}\Big|_{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}
\cdot
J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0})
=
-\sum_{i=1}^{n}
\frac{\partial \rho}{\partial \tilde{e}_{i}}\Big|_{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})}
\cdot
J_{i}^{\top}J_{i}\mathbf{\delta}
\end{align}\]
\[\begin{split}\begin{align}
b &= \sum_{i=1}^{n}
w_{i}
\cdot
J_{i}^{\top}\mathbf{r}_{i}(\mathbf{\beta}_{0}) \\
A &=
-\sum_{i=1}^{n}
w_{i}
\cdot
J_{i}^{\top}J_{i} \\
w_{i} &= \frac{\partial \rho}{\partial \tilde{e}_{i}}\Big|_{\tilde{e}_{i}(\mathbf{\beta}_{0} + \mathbf{\delta})} \\
A\mathbf{\delta} &= b
\end{align}\end{split}\]
この線型方程式を解けば \(\mathbf{\beta}_{0}\) の周辺で \(E_{\rho}(\mathbf{\beta})\) を近似的に最小化させるパラメータ \(\mathbf{\beta}_{0} + \mathbf{\delta}^{*},\, \mathbf{\delta}^{*} = A^{-1}b\) を見つけることができる。
あとは通常のGauss-Newton法と同じように \(\mathbf{\beta}_{m+1} = \mathbf{\beta}_{m} + \mathbf{\delta}\) とし、誤差関数 \(E_{\rho}\) を最小化する操作を誤差またはパラメータの変化が収束するまで繰り返せばよい。